On stage in Stockholm, Sweden, Tuesday, Jan 24th, Nvidia CEO Jensen Huang celebrated that there are 600 AI startups in Sweden. He has spent a few days in Sweden, and last night he held an “AI ecosystem reception” in downtown Stockholm. He was interviewed on stage by Marcus Wallenberg, who chairs companies like SEB and Saab. What struck me was how important it is that major business leaders like Marcus Wallenberg are up to date with the latest technology thanks to their relationships with tech leaders like Jensen Huang. That probably is one of the reasons why the Knut and Alica Wallenberg foundation has invested so much in AI through the WASP program here in Sweden. Jensen also talked about how they first met years ago and how Marcus quickly read up on the latest developments based on their meetings.

Jensen highlighted a few major points in his speech:
For AI models, we have seen an improvement of 3000 times over the last 10 years compared to Moore’s law which predicted around 100 times improvement. One major reason is of course, GPU performance.
We now see large generative models working not only on text and images but also on things like protein.
He argued that what we are experiencing now is a new type of computing platform where data is creating the software instead of a human writing code.
During Jensen’s visit here in Sweden, it was also announced that the Nvidia-power supercomputer Berzelius will get an upgrade. The system consists of 60 Nvidia DGX A100 systems connecting 1,5 petabytes of flash memory using the Nvidia Mellanox Infiniband HDR network. The initial system was made possible by a separate donation of 300 million SEK ($36 million) from the Knut and Alicia Wallenberg foundation. The upgrade will add an additional 34 Nvidia DGX A100 systems to the cluster.
So why is this system relevant for the development of AI-assisted tools for analysis? Well, also this week, there was an announcement from AI Sweden of the pre-release version of a GPT-3 model trained on Swedish and Nordic text content. It is the same kind of model that is powering the now famous ChatGPT system everybody was talking about at the end of 2022. That model, called GPT-SW3, was trained on this Nvidia-power supercomputer called Berzelius. These large language models (LLM) require substantial computational power and storage capacity to be trained efficiently, and that is the reason why they previously were not available for minor languages like Swedish. I look forward to seeing what innovations can be made through models like this trained in Sweden by researchers and people from AI Sweden and the WASP WARA Media and Language Arena. It will mean it will be much easier to implement solutions for the analysis of texts and also the generation of texts based on prompts in Swedish.

Sara Mazur
It was also inspiring to see yet again all the plans for the WASP Program presented by Sara Mazur. Sara is the Vice Executive Director Knut and Alice Wallenberg Foundation (KAW) and Chair Wallenberg AI, Autonomous Systems and Software Program (WASP). The program attracts to researchers from all over the world who form research groups and will lead to close to 700 new PhDs. Great skills that can contribute to advancing research and implementation of AI in Sweden and beyond.
Staffan Truvé
Also on stage last night was Staffan Truvé, co-founder and CTO of Recorded Future. Recorded Future claims they are the World’s Largest Intelligence Company focusing on the cyber threat domain. Staffan pointed out that just as Google organized the world’s information for search, Recorded Future has organized cyber threat data in a massive Intelligence Graph. In essence, it becomes a digital twin of threats in the world.
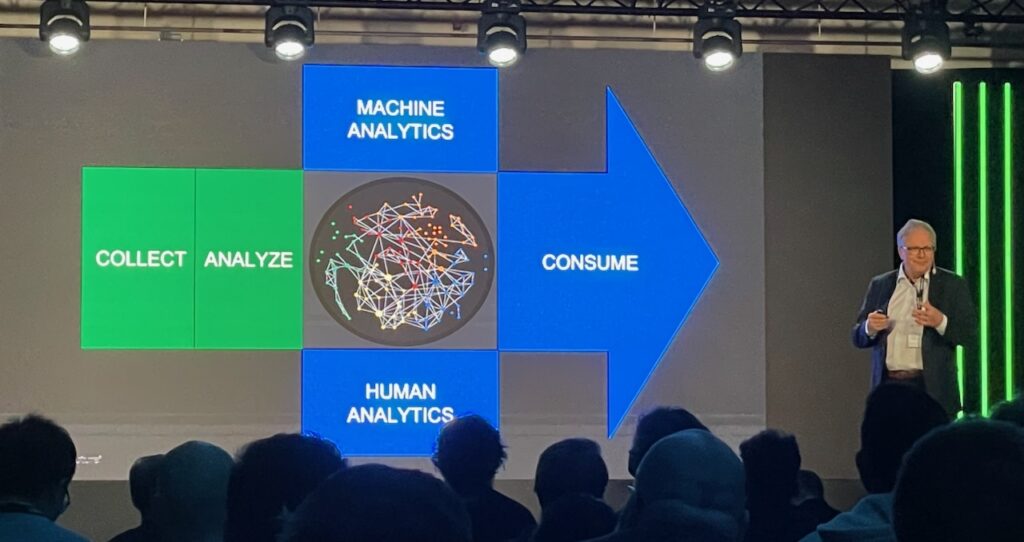
What resonated with me was the way he pointed out that the primary foundation is to organize the information in a Knowledge Graph and then use humans and machines together to analyze the data. Routine (dull) work can be done by machines and leaving analysts to have more time to think as we say here @Parsd. He also talked about how Recorded Future started by manually creating rules for their platform that worked surprisingly well. However, the amount of information leads to a need to switch over to machine learning-based automation to handle this. The approach now is based on Daniel Kahneman’s concept of having a machine learning-based “perceptive system” doing Classification & Categorization while a Rule-based “reasoning system” does the logic reasoning. He ended by stating three things:
We’ve never had as much data
We’ve never had as much computer power
We’ve never had as much open source software
He concluded by asking. What’s your story?
Our story is to harness the power of this to provide analysts with an optimized workflow for their unstructured data so they can make trusted insights that matter to people making decisions.
Read more about the event on the Nvidia Blog.
Why AI is relevant for the analytical workflow?
At Parsd, we believe the latest advances in AI make it possible to work in new ways with unstructured information. It used to be manually reading through text and then editing manually in a word processor. Using state-of-the-art Natural Language Processing (NLP), we can summarize, categorize and extract data from text. We believe that it makes it possible to ask new types of “questions” to text and make it possible to create or extract structure from text data. The combination of machines being able to process vast amount of text data together with efficient human analytical work makes it possible to create new types of analytical products based on vastly more underlying data than is possible with just manual methods. At Parsd, we use both existing pre-trained NLP models but are also developing capabilities to be able to adapt our NLP to domain-specific needs. Later on, we will also apply AI to images, speech and video content.